



An order-of-magnitude leap for accelerated computing.
Tap into unprecedented performance, scalability, and security for every workload with the NVIDIA H100 Tensor Core GPU. With NVIDIA® NVLink® Switch System, up to 256 H100s can be connected to accelerate exascale workloads, along with a dedicated Transformer Engine to solve trillion-parameter language models. H100’s combined technology innovations can speed up large language models by an incredible 30X over the previous generation to deliver industry-leading conversational AI.

-
Ready for Enterprise AI?
Enterprise adoption of AI is now mainstream, and organizations need end-to-end, AI-ready infrastructure that will accelerate them into this new era.
H100 for mainstream servers comes with a five-year subscription, including enterprise support, to the NVIDIA AI Enterprise software suite, simplifying AI adoption with the highest performance. This ensures organizations have access to the AI frameworks and tools they need to build H100-accelerated AI workflows such as AI chatbots, recommendation engines, vision AI, and more.
-
Securely accelerate workloads from enterprise to exascale.
Transformational AI training.
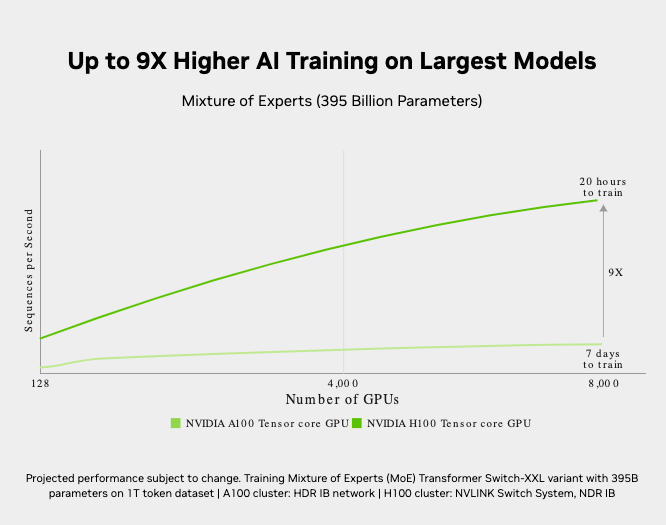
H100 features fourth-generation Tensor Cores and the Transformer Engine with FP8 precision that provides up to 9X faster training over the prior generation for mixture-of-experts (MoE) models. The combination of fourth-generation NVlink, which offers 900 gigabytes per second (GB/s) of GPU-to-GPU interconnect; NVLINK Switch System, which accelerates communication by every GPU across nodes; PCIe Gen5; and NVIDIA Magnum IO™ software delivers efficient scalability from small enterprises to massive, unified GPU clusters.
Deploying H100 GPUs at data center scale delivers outstanding performance and brings the next generation of exascale high-performance computing (HPC) and trillion-parameter AI within the reach of all researchers.
-
Real-time deep learning inference.
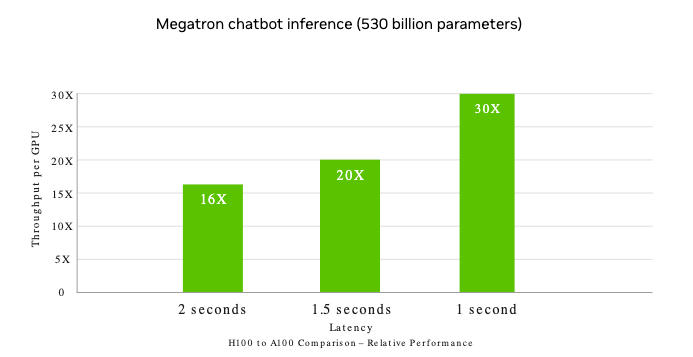
Up to 30X higher AI inference performance on the largest models.
AI solves a wide array of business challenges, using an equally wide array of neural networks. A great AI inference accelerator has to not only deliver the highest performance but also the versatility to accelerate these networks.
H100 further extends NVIDIA’s market-leading inference leadership with several advancements that accelerate inference by up to 30X and deliver the lowest latency. Fourth-generation Tensor Cores speed up all precisions, including FP64, TF32, FP32, FP16, and INT8, and the Transformer Engine utilizes FP8 and FP16 together to reduce memory usage and increase performance while still maintaining accuracy for large language models.
-
Exascale high-performance computing.
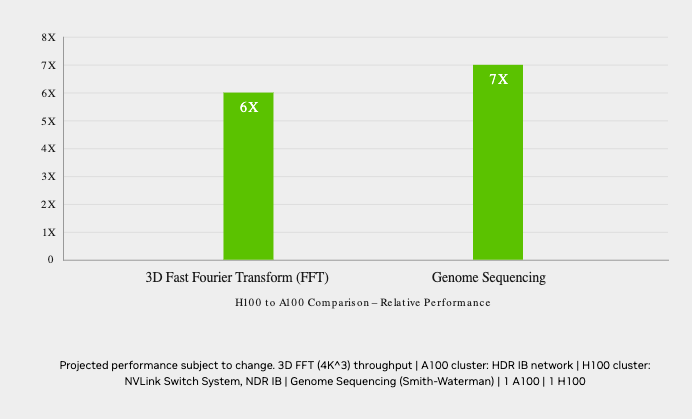
Up to 7X higher performance for HPC applications.
The NVIDIA data center platform consistently delivers performance gains beyond Moore’s Law. And H100’s new breakthrough AI capabilities further amplify the power of HPC+AI to accelerate time to discovery for scientists and researchers working on solving the world’s most important challenges.
H100 triples the floating-point operations per second (FLOPS) of double-precision Tensor Cores, delivering 60 teraFLOPS of FP64 computing for HPC. AI-fused HPC applications can leverage H100’s TF32 precision to achieve one petaFLOP of throughput for single-precision, matrix-multiply operations, with zero code changes.
H100 also features DPX instructions that deliver 7X higher performance over NVIDIA A100 Tensor Core GPUs and 40X speedups over traditional dual-socket CPU-only servers on dynamic programming algorithms, such as Smith-Waterman for DNA sequence alignment.
-
Accelerated
data analytics.
Data analytics often consumes the majority of time in AI application development. Since large datasets are scattered across multiple servers, scale-out solutions with commodity CPU-only servers get bogged down by a lack of scalable computing performance.
Accelerated servers with H100 deliver the compute power—along with 3 terabytes per second (TB/s) of memory bandwidth per GPU and scalability with NVLink and NVSwitch—to tackle data analytics with high performance and scale to support massive datasets. Combined with NVIDIA Quantum-2 Infiniband, the Magnum IO software, GPU-accelerated Spark 3.0, and NVIDIA RAPIDS™, the NVIDIA data center platform is uniquely able to accelerate these huge workloads with unparalleled levels of performance and efficiency.
-
Enterprise-ready
utilization.
IT managers seek to maximize utilization (both peak and average) of compute resources in the data center. They often employ dynamic reconfiguration of compute to right-size resources for the workloads in use.
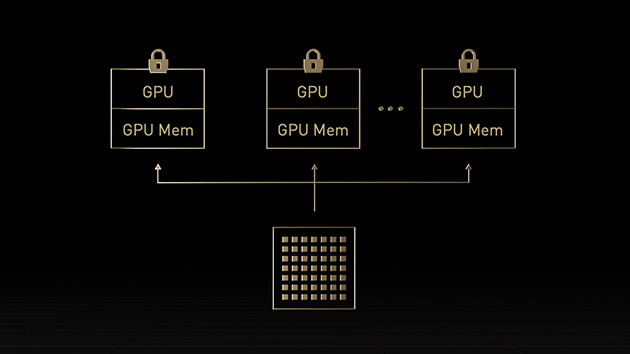
Second-generation Multi-Instance GPU (MIG) in H100 maximizes the utilization of each GPU by securely partitioning it into as many as seven separate instances. With confidential computing support, H100 allows secure end-to-end, multi-tenant usage, ideal for cloud service provider (CSP) environments.
H100 with MIG lets infrastructure managers standardize their GPU-accelerated infrastructure while having the flexibility to provision GPU resources with greater granularity to securely provide developers the right amount of accelerated compute and optimize usage of all their GPU resources.
-
Built-in
confidential computing.
Today’s confidential computing solutions are CPU-based, which is too limited for compute-intensive workloads like AI and HPC. NVIDIA Confidential Computing is a built-in security feature of the NVIDIA Hopper™ architecture that makes H100 the world’s first accelerator with confidential computing capabilities. Users can protect the confidentiality and integrity of their data and applications in use while accessing the unsurpassed acceleration of H100 GPUs. It creates a hardware-based trusted execution environment (TEE) that secures and isolates the entire workload running on a single H100 GPU, multiple H100 GPUs within a node, or individual MIG instances. GPU-accelerated applications can run unchanged within the TEE and don’t have to be partitioned. Users can combine the power of NVIDIA software for AI and HPC with the security of a hardware root of trust offered by NVIDIA Confidential Computing.
-
Unparalleled performance for
large-scale AI and HPC.
The Hopper Tensor Core GPU will power the NVIDIA Grace Hopper CPU+GPU architecture, purpose-built for terabyte-scale accelerated computing and providing 10X higher performance on large-model AI and HPC. The NVIDIA Grace CPU leverages the flexibility of the Arm® architecture to create a CPU and server architecture designed from the ground up for accelerated computing. The Hopper GPU is paired with the Grace CPU using NVIDIA’s ultra-fast chip-to-chip interconnect, delivering 900GB/s of bandwidth, 7X faster than PCIe Gen5. This innovative design will deliver up to 30X higher aggregate system memory bandwidth to the GPU compared to today's fastest servers and up to 10X higher performance for applications running terabytes of data.
Sale!








NVIDIA H100 Enterprise PCIe-4 80GB
$31,000.00 – $31,800.00
Unprecedented performance, scalability, and security for every data center. Designed for deep learning and special workloads.
The SXM4 (NVLINK native soldered onto carrier boards) version of the cards are available upon request only, and are attached permanently to their respective motherboards via a complete system only, with longer lead times.
Verify with live chat agent in advance for availability as stock and pricing is volatile and changes every 24-48 hours. All sales final. No returns or cancellations. For bulk inquiries, consult a live chat agent or call our toll-free number.




| Form Factor | H100 SXM | H100 PCIe |
|---|---|---|
| FP64 | 34 teraFLOPS | 26 teraFLOPS |
| FP64 Tensor Core | 67 teraFLOPS | 51 teraFLOPS |
| FP32 | 67 teraFLOPS | 51 teraFLOPS |
| TF32 Tensor Core | 989 teraFLOPS* | 756teraFLOPS* |
| BFLOAT16 Tensor Core | 1,979 teraFLOPS* | 1,513 teraFLOPS* |
| FP16 Tensor Core | 1,979 teraFLOPS* | 1,513 teraFLOPS* |
| FP8 Tensor Core | 3,958 teraFLOPS* | 3,026 teraFLOPS* |
| INT8 Tensor Core | 3,958 TOPS* | 3,026 TOPS* |
| GPU memory | 80GB | 80GB |
| Dimensions | |
|---|---|
| Depth | 11.1 cm |
| Height | 3.47 cm |
| Weight | 1.69 kg |
| Width | 26.7 cm |
Only logged in customers who have purchased this product may leave a review.



Reviews
There are no reviews yet.