



AI Inference and Mainstream Compute for Every Enterprise
Bring accelerated performance to every enterprise workload with NVIDIA A30 Tensor Core GPUs. With NVIDIA Ampere architecture Tensor Cores and Multi-Instance GPU (MIG), it delivers speedups securely across diverse workloads, including AI inference at scale and high-performance computing (HPC) applications. By combining fast memory bandwidth and low-power consumption in a PCIe form factor—optimal for mainstream servers—A40 enables an elastic data center and delivers maximum value for enterprises.

-
The Data Center Solution
for Modern IT
The NVIDIA Ampere architecture is part of the unified NVIDIA EGX™ platform, incorporating building blocks across hardware, networking, software, libraries, and optimized AI models and applications from the NVIDIA NGC™ catalog. Representing the most powerful end-to-end AI and HPC platform for data centers, it allows researchers to rapidly deliver real-world results and deploy solutions into production at scale.
-
DEEP LEARNING
TRAINING
Training AI models for next-level challenges such as conversational AI requires massive compute power and scalability.
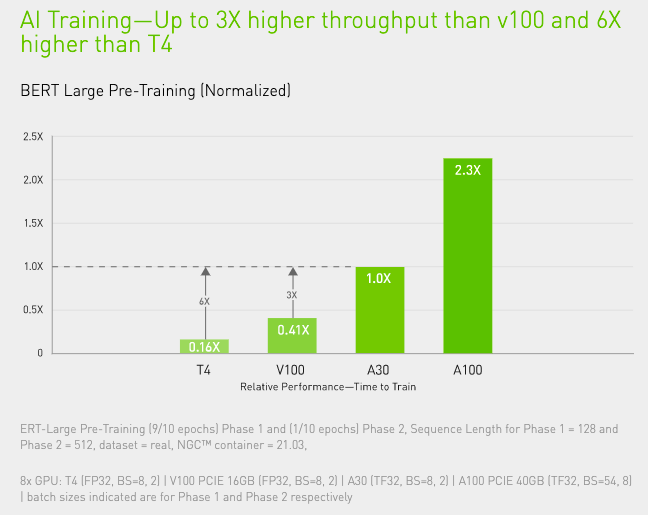
NVIDIA A40 Tensor Cores with Tensor Float (TF32) provide up to 10X higher performance over the NVIDIA T4 with zero code changes and an additional 2X boost with automatic mixed precision and FP16, delivering a combined 20X throughput increase. When combined with NVIDIA® NVLink®, PCIe Gen4, NVIDIA networking, and the NVIDIA Magnum IO™ SDK, it’s possible to scale to thousands of GPUs.
Tensor Cores and MIG enable A30 to be used for workloads dynamically throughout the day. It can be used for production inference at peak demand, and part of the GPU can be repurposed to rapidly re-train those very same models during off-peak hours.
NVIDIA set multiple performance records in MLPerf, the industry-wide benchmark for AI training.
-
HIGH-PERFORMANCE
DATA ANALYTICS
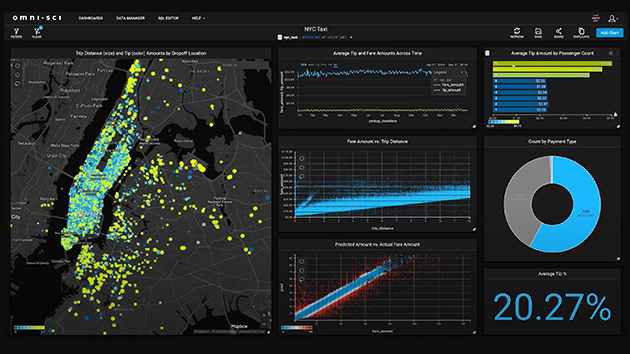
Data scientists need to be able to analyze, visualize, and turn massive datasets into insights. But scale-out solutions are often bogged down by datasets scattered across multiple servers.
Accelerated servers with A40 provide the needed compute power—along with large HBM2 memory, 933GB/sec of memory bandwidth, and scalability with NVLink—to tackle these workloads. Combined with NVIDIA InfiniBand, NVIDIA Magnum IO and the RAPIDS™ suite of open-source libraries, including the RAPIDS Accelerator for Apache Spark, the NVIDIA data center platform accelerates these huge workloads at unprecedented levels of performance and efficiency.
-
ENTERPRISE-READY
UTILIZATION
A30 with MIG maximizes the utilization of GPU-accelerated infrastructure. With MIG, an A40 GPU can be partitioned into as many as four independent instances, giving multiple users access to GPU acceleration.
MIG works with Kubernetes, containers, and hypervisor-based server virtualization. MIG lets infrastructure managers offer a right-sized GPU with guaranteed QoS for every job, extending the reach of accelerated computing resources to every user.
DEEP LEARNING INFERENCE
A30 leverages groundbreaking features to optimize inference workloads. It accelerates a full range of precisions, from FP64 to TF32 and INT4. Supporting up to four MIGs per GPU, A30 lets multiple networks operate simultaneously in secure hardware partitions with guaranteed quality of service (QoS). And structural sparsity support delivers up to 2X more performance on top of A30’s other inference performance gains.
NVIDIA’s market-leading AI performance was demonstrated in MLPerf Inference. Combined with NVIDIA Triton™ Inference Server, which easily deploys AI at scale, A30 brings this groundbreaking performance to every enterprise.
-
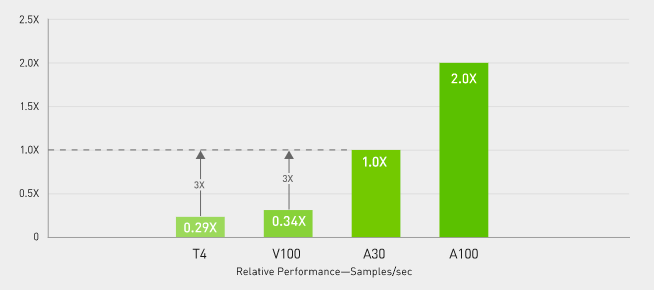
AI Inference—Up To 3X higher throughput than V100 at real-time conversational AI
BERT Large Inference (Normalized)
Throughput for <10ms Latency -
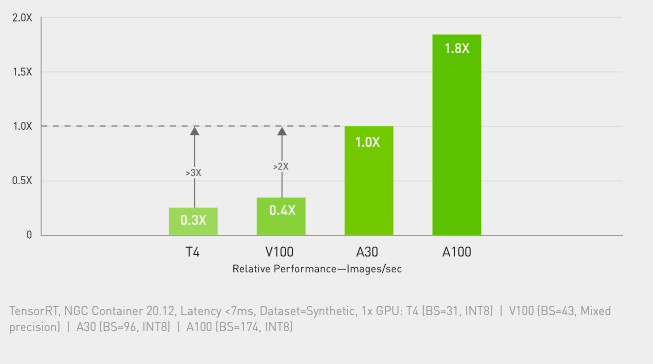
AI Inference—Over 3X higher throughput than T4 at real-time image classification
RN50 v1.5 Inference (Normalized)
Throughput for <7ms Latency -
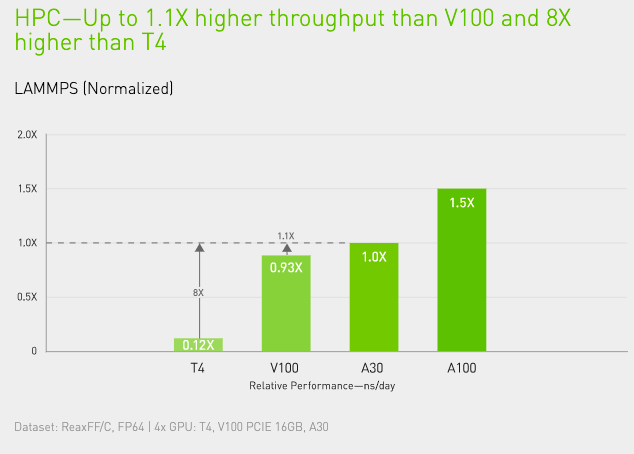
HIGH-PERFORMANCE COMPUTING
To unlock next-generation discoveries, scientists use simulations to better understand the world around us.
NVIDIA A30 features FP64 NVIDIA Ampere architecture Tensor Cores that deliver the biggest leap in HPC performance since the introduction of GPUs. Combined with 24 gigabytes (GB) of GPU memory with a bandwidth of 933 gigabytes per second (GB/s), researchers can rapidly solve double-precision calculations. HPC applications can also leverage TF32 to achieve higher throughput for single-precision, dense matrix-multiply operations.
The combination of FP64 Tensor Cores and MIG empowers research institutions to securely partition the GPU to allow multiple researchers access to compute resources with guaranteed QoS and maximum GPU utilization. Enterprises deploying AI can use A30’s inference capabilities during peak demand periods and then repurpose the same compute servers for HPC and AI training workloads during off-peak periods.






NVIDIA A40 Enterprise Tensor Core 48GB 190W
$6,295.00
Bring accelerated performance to every enterprise workload with NVIDIA A40 Tensor Core GPUs. With NVIDIA Ampere architecture Tensor Cores and Multi-Instance GPU (MIG), it delivers speedups securely across diverse workloads, including AI inference at scale and high-performance computing (HPC) applications. By combining fast memory bandwidth and low-power consumption in a PCIe form factor—optimal for mainstream servers—A30 enables an elastic data center and delivers maximum value for enterprises.
Ships in 10 days after payment. All sales final. No returns or cancellations. For volume pricing, consult a live chat agent or call our toll-free number.
44 in stock



| FP64 | 5.2 teraFLOPS |
| FP64 Tensor Core | 10.3 teraFLOPS |
| FP32 | 10.3 teraFLOPS |
| TF32 Tensor Core | 82 teraFLOPS | 165 teraFLOPS* |
| BFLOAT16 Tensor Core | 165 teraFLOPS | 330 teraFLOPS* |
| FP16 Tensor Core | 165 teraFLOPS | 330 teraFLOPS* |
| INT8 Tensor Core | 330 TOPS | 661 TOPS* |
| INT4 Tensor Core | 661 TOPS | 1321 TOPS* |
| Media engines | 1 optical flow accelerator (OFA) 1 JPEG decoder (NVJPEG) 4 video decoders (NVDEC) |
| GPU memory | 48GB HBM2 |
| GPU memory bandwidth | 933GB/s |
| Interconnect | PCIe Gen4: 64GB/s Third-gen NVLINK: 200GB/s** |
| Form factor | Dual-slot, full-height, full-length (FHFL) |
| Max thermal design power (TDP) | 165W |
| Multi-Instance GPU (MIG) | 4 GPU instances @ 6GB each 2 GPU instances @ 12GB each 1 GPU instance @ 24GB |
| Virtual GPU (vGPU) software support | NVIDIA AI Enterprise NVIDIA Virtual Compute Server |
Download
Only logged in customers who have purchased this product may leave a review.



Reviews
There are no reviews yet.